These are elaborate notes on a “Tech Tonic” talk given at Pramati Technologies, Chennai, on 23rd July 2015. The organization of this post reflects the talk itself.
Functional programming has been gaining deeper penetration in the software
development world in the recent years owing to increased need for maintainable
large scale software development with scalable performance characteristics.
Research papers on type theory, data structures, reactive programming and such
remain relatively inaccessible to the programming community at large and
explanatory material on the web tends to focus on various language and library
features such as “lambda functions”, “laziness”, “algebraic data types”,
“monads”, “monoids” or “functors”. Consequently, programmers coming from an
“object oriented” background are confused by the variety of views and concepts
and find it difficult to negotiate the paradigm, unable to make use of it ‘cos
their work language is considered “not functional”, or are just lost on why FP
matters. This talk was another an attempt to add to the confusion
address this gap by highlighting notations developed for FP that are useful
general purpose thinking tools for system design that can be used irrespective
of the implementation language.
Status: Draft
Structure and agenda
This talk is based on the observation that the biggest hurdle that most programmers entering the world of FP face is not the plethora of new concepts they encounter, but rather a different way of thinking about systems that they need to get familiar with first. Hence the title “functional thinking” as opposed to “functional programming”. My intention is to show how this approach is useful irrespective of the language your daily work is done in.
One of the important developments in the world of FP is the adoption of a common notation for expressing concepts in academic papers. The rest of the programming community, especially those coming from more traditional imperative languages, end up not seeing how this notation can augment their thinking about systems. So another intention of mine is to focus on this notation and its details. I’ll use a few examples to illustrate how to “think with” this notation.
Thinking about systems in “the functional way” leads to a few common engineering patterns. I’ll point out some of these patterns along with examples. One of these patterns - “control flow” - turns out to be a very large topic and I hope to cover that in another talk+post.
Before I get to all that, I want to get something out of the way first ..
False dichotomies
The “object oriented programming” and “functional programming” approaches come with their own rich vocabulary. In OOP, we encounter “encapsulation”, “inheritance”, “objects”, “class”, “metaclass”, “method”, “member”, “message”, “property”, “dependency injection”, “virtual method”, “prototype” and so on. In FP, we encounter “function”, “closure”, “immutable”, “referential transparency”, “currying”, “purity”, “applicative”, “monad”, “monoid”, “functor”, “lazy”, “type classes”, “arrows”, “declarative”, “category”, “laziness” and so on.
It is remarkable how little overlap there is in the terminology between these approaches, both dealing with programming. This has led to some false dichotomies that end up distracting engineers from reaping the benefits of either approach to thinking about systems.
The biggest of these false dochotomies is “FP vs. OOP” itself. Now, should you need to choose to learn only one of the two? Should a physics student only bother to learn quantum mechanics? If you get past that, we have “Functions vs. Classes” fights and “Closures vs. Objects” fights which especially take place in languages that support both ways of thinking.
The best expression of these being false dichotomies that I’ve found is Anton Van Straaten’s koan. I hate to paraphrase it and will just reproduce it below –
The venerable master Qc Na was walking with his student, Anton. Hoping to prompt the master into a discussion, Anton said “Master, I have heard that objects are a very good thing - is this true?” Qc Na looked pityingly at his student and replied, “Foolish pupil - objects are merely a poor man’s closures.”
Chastised, Anton took his leave from his master and returned to his cell, intent on studying closures. He carefully read the entire “Lambda: The Ultimate…” series of papers and its cousins, and implemented a small Scheme interpreter with a closure-based object system. He learned much, and looked forward to informing his master of his progress.
On his next walk with Qc Na, Anton attempted to impress his master by saying “Master, I have diligently studied the matter, and now understand that objects are truly a poor man’s closures.” Qc Na responded by hitting Anton with his stick, saying “When will you learn? Closures are a poor man’s object.” At that moment, Anton became enlightened.
(By Anton Van Straaten in a 2003 discussion thread with Guy Steele.)
Here on, I’m assuming that the reader is at least on her way to such an enlightenment and chooses not to take sides in this lose-lose battle.
What is functional thinking?
Having declared these dichotomies as false, how do we identify functional thinking? At least for the purpose of this post/talk, I’d like to express it as –
Functional Thinking is thinking about systems based on a mathematical foundation.
To elaborate, we’ll be looking at ways to think about the systems that we build, and we want to be able develop our understanding about the domain for which we’re building these systems with the same clarity that we get when we translate verbal statements of problems into mathematical form. The other way to think about systems is to learn a lot of folklore about what has worked or not in the past and carefully examine and apply these lessons to the new problem domain we’re faced with. While such a folklore driven approach can also work if the understanding is combined with experience to create the wisdom about when to apply what principle and in what measure, I’m intrigued by the possibility that, with a small set of mathematical principles, anyone can describe and reason about their system with confidence. To me, the FP approach being developed feels like this Newtonian breakthrough in capturing what otherwise looked to be a wide variety of phenomena in a small set of laws. So this is the approach I hope to describe in this talk.
To clarify, I’m not proposing something new here. Just restating, re-emphasizing what is commonly lost in translation, and so on.
Tools for functional thinking
Functions are central to this approach, of course. Also, modern notation for functions and for describing their types are very powerful tools that let us think about our systems in the abstract.
It is important to clarify what “function” means here. I use the word “function” in the mathematical sense - i.e. a relation that associates elements from one set of objects to corresponding elements in another set of objects. Each element in the first set has a corresponding element in the second set. The way computing gets in here is that it is in general impractical to always define functions by exhaustively specifying pairs of objects related in a specific manner. It is much more practical to provide a procedure that identifies an element of the second set given an element from the first set. So, for the purpose of this talk, we will not distinguish between functions specified using either approach and consider them to be equivalent.
The other important aspect is the modern notation for composing expressions using functions and for describing the types of functions and expressions composed using them. Before diving into that, I’d like to take a detour to talk about why a good notation can itself a leap.
The importance of good notation
Good notation for a previously hard to tackle domain is like technology for the mind. Here are a couple of examples.
Roman numerals versus the place value system
Roman numerals were the conventional form of number notation in the hey days of Roman empire. What we’d write today as “121 X 11 = 1331” might’ve been expressed as “cxxi X xi = mcccxxxi”. “m” is 1000, c" is 100, “x” is 10 and “i” is 1 so “cxxi” is 100 + 20 + 1, “xi” is 10+1 and “mcccxxxi” is 1000+3x100+3x10+1.
This is reasonable .. until you begin to consider larger numbers. You run out of letters soon after “m”. So expressing “128 X 256 = 32768” would be something like “cxxviii X cclvi = mmm…xxxii times…mmdclxviii”. This is when the place value notation begins to shine brighter. The place value notation quite directly lets us think about much larger numbers like “1,000,000,000,000” even though our brains didn’t evolve to handle them by magnitude. It is indeed serving the function we attribute to technology - that of augmenting and amplifying our otherwise limited abilities.
The place value notation also points out another important attribute of good notation - it hides complex regularities under forms that are simple to think with. For example, when we write “32768”, we actually mean “3 X 10^4 + 2 X 10^3 + 7 X 10^2 + 6 X 10^1 + 8 X 10^0”. The underlying meaning has regular rules of operation behind it, which translate into regular rules of operation on the sequential symbols we use to express numbers in the place value notation. This regularity can even be extended to cover fractional numbers.
Given an option, would you choose to revert to the roman numeral system?
Calculus and the laws of gravity
Newton is known to have pretty much invented calculus in order to work with and express his observations about gravity. While there was much controversy about whether Leibniz or Newton is to be credited for calculus, that is not relevant to the point of our discussion so we won’t go there. Below is Newton’s law of motion in a gravitational field expressed in the notation of modern calculus.
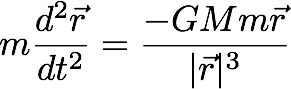
When applying this to the solar system, we use “M” to refer to the mass of the sun and “m” to the mass of a planet whose orbit around the sun we’re considering. Lets look at a few things we can infer from the equation without having to solve it in closed form, which is possible only for some limited cases anyway.
Since “m” is common to both sides of the equation, we cancel it out on both sides.
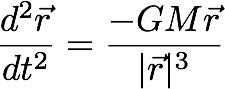
What does this mean? It means that a tennis ball and a feather in orbit around the earth near each other and moving with the same velocity will move along the same orbit around the earth over small enough time intervals. In particular, they will appear to be at rest relative to each other as they orbit the earth. The two “m"s are also not really the same. One is an “inertial mass” - the mass responsible for resting change to state of motion and the other is a “gravitational mass” - the mass responsible for the gravitational pull. Canceling the two therefore is an assertion that “inertial mass = gravitational mass”, which forms the basis of general relativity - that free fall in a gravity field is indistinguishable from an inertial reference frame and an accelerated reference frame is indistinguishable from a frame with a uniform gravitational field.
Now let’s make the following simple substitutions -
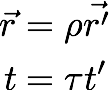
What we’re doing here is changing the scale of space and time independently. If we then rearrange the equation, we get –
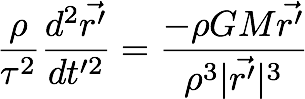
If we then let both the scaling factors be related to each other like below, we see that the equation turns out to take the same form as the original equation, only with the substituted position vector and time.
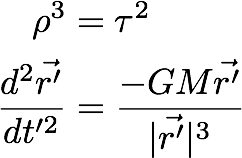
This means that once we have one solution, we can generate more solutions to the equation by just scaling the existing solution appropriately. For the keen-eyed, this relationship is Kepler’s third law of planetary motion - the statement that the square of time period of orbit of planets around the sun is proportional to the cube of the semi-major axis of their orbits.
There is more gold to be mined from these equations, but we’ll stop here for now.
Again, the notation of calculus (despite many criticisms) surfaces just enough of the underlying machinery of infinitesimals, which are notorious to describe precisely, and provides a pleasant integration with algebra. This lets us work with equations that describe systems with way more complicated dynamics than we were able to deal with analytically prior to the invention of the notation. Furthermore, this notation is teachable at a much lower level of mathematical sophistication than those who were responsible for developing it.
PS: This was presented by Prof. V. Balakrishnan at a talk I attended as a school kid (I think) in 1991 or 1992 at P.S.Senior Secondary School in Chennai. It was largely responsible for my interest in mathematical physics.
We now look at the modern notation for functions, their types and some important algebraic properties of these.
Notation for functions
To recap, we start with the mathematical notion of the word “function” - a relation between two sets of objects such that given an object from the “domain set”, the function identifies a unique object in the “range set”. Furthermore, for our purpose, we choose not to distinguish between a machinery that in effect produces such an association and the mathematical function that it implies. Remember, the “objects” in these sets can be anything (do not confuse with “object” in OOP), including function machinery.
Let’s start with the above first. To express the fact that an object x is from
a domain X, and an object y is from a domain Y, we write -
x :: X
y :: Y
We can now talk about “the set of functions from X to Y”. If f is a function from
such a set, we write it as -
f :: X -> Y
In words, X -> Y is the notation for the set of functions from X to Y.
While our intention is to deal with mathematical functions, we use the same
notation to also refer to machinery that produces such an association.
We notate the “application” of a function to an object like so -
y = f x
x :: X
y :: Y
f :: X -> Y
f x :: Y
which says “the object y lies in the set Y and is associated with the
object x from the domain X through the function f”. That’s quite a
mouthful that you don’t have to utter whenever you see y = f x. If you’ve
missed it, we’re using capitalized letters to denote domains/sets and lower
case letters to denote objects from these sets.
Now we can do some interesting algebra with just this much.
What does X -> (Y -> Z) mean? This is “the set of functions from X to the
set of functions from Y to Z”. What does (X -> Y) -> Z mean? This is the
set of functions from X -> Y to Z.
We make a simplification to the notation by adopting the convention that
whenever we’re writing down something of the form X -> (Y -> Z), we can drop
the parentheses and just write X -> Y -> Z. In other words, we’re treating
the -> operator as “right associative”.
An application of a function in X -> Y -> Z would look like this -
z = (f x) y
We extend the “drop parentheses” convention to this case as well and simply write -
z = f x y
with the understanding that f must first be applied to x to get a function
which is then applied to y to get z. This would then be our model of “functions
with multiple arguments”.
So what?
Both in mathematics and in programming, we’re used to writing function applications in one of the following forms -
f(x,y) -- in mathematics and in languages like C.
f[x,y] -- as in Mathematica
(f x y) -- as in all Lisp systems
So the question of “why bother introducing a different notation?” is a legitimate one. To see this, we consider what happens as we write down 3-argument, 2-argument, 1-argument and 0-argument functions in all these notations. Here goes -
f(x,y,z) ... f(x,y) ... f(x) ... f()
f[x,y,z] ... f[x,y] ... f[x] ... f[]
(f x y z) ... (f x y) ... (f x) ... (f)
f x y z ... f x y ... f x ... f
While the 3/2/1-argument forms are correspondent, we see a discrepancy in the
0-argument forms. Our new notation does not permit us to distinguish between
the following two concepts - a) a function applied to no arguments, and b)
the function as a value. When we wrote down x to denote an object from a domain X,
we weren’t particularly thinking of it as “a function applied to no arguments to
produce an object in the domain X”. So, in our new notation, “a function applied
to zero arguments” is just a value, a constant.
While this might appear to be a restriction, this is a restriction that lets us reason about systems with confidence, as our notation itself imposes this constraint of “purity” on us. We’ll see how this purity can simplify our thinking about various systems.
Application: Image processing
We’ll start with a simple application of functional thinking - representing and manipulating images like in Photoshop.
We first ask “What is an image?”. This simple question already illustrates stark differences in how one would approach an answer the traditional OOP way versus when you’re thinking functionally.
An OOP answer might look like “an image consists of a set of pixels laid out in an array, it has properties of width and height in pixel units” … and so on. We’re taught to look and objects as a collection of properties and data and methods to operate on this object.
How would you approach this using only the notation we’ve introduced thus far?
We want to describe a type Image. One way to add some detail to this picture
(pun not intended) is to use -> to split an image into two parts - 1) a description
of a location in the image and 2) the colour at that location. We might write this as -
type Image = Coordinates -> Colour
i.e. we’re treating images as functions from coordinates to colour. If we use (X,Y)
to denote “the set of pairs of elements from X and Y”, we can write -
type Coordiantes = (Number, Number)
type Image = Coordinates -> Colour
If we now permit ourselves to use the same function application notation to generalize this kind of a concept, we can write a “type equation” like so -
type Image coords colour = coords -> colour
and use Image (Number,Number) ARGB to refer to a 2-dimensional image with a
4-dimensional colour space.
We’ve done something significant here without even realizing it. When we wrote
the type equation for Image, we’ve abstracted away its internal structure.
While we may model an image today as a function from coordinates to colour,
we’re not bound to stick to this if we need a different representation for
reasons such as efficiency of implementation. In the above type expression,
coords and colour are “type variables” that we notate using lower case
letters and Image is a “type constructor” - much like a function that
produces types.
With this notation in our bag, we can now express a few common operations we want to do with images. We’ll use a specific notion of image and leave the generalization as homework.
type Image = (Float, Float) -> Color
shift :: (Float, Float) -> Image -> Image
shift (dx, dy) inputImg =
λ (x,y) ->
inputImg (x - dx, y - dy)
invert :: Image -> Image
invert img =
λ (x,y) ->
let (a,r,g,b) = img (x,y)
in (a, 1.0-r, 1.0-g, 1.0-b)
compose :: Image -> Image -> Image
compose im1 im2 =
λ (x,y) ->
let (a1,r1,g1,b1) = im1 (x, y)
(a2,r2,g2,b2) = im2 (x, y)
a = a1 + a2
in
(a,
(a1 * r1 + a2 * r2) / a,
(a1 * g1 + a2 * g2) / a,
(a1 * b1 + a2 * b2) / a)
If you take a step back and observe what we’re doing here, we’re diving directly into modeling the domain of images. At first, it looks like we disregard efficiency considerations. However, it is rather pointless to have an efficient implementation of the wrong thing.
So a way to get the domain modeled well is a valuable step to take at first. Once we’re confident of our domain model, we can use a well understood pattern to produce efficient implementation without sacrificing much of the abstraction we’ve enjoyed thus far. This can be called the “layering” approach where the job of one software layer is to produce instructions for a second implementation layer. In our case, if we take this implementation layer to be GPUs, we can rewrite our functions to produce “fragment shaders” which are handed over to the GPU to perform the necessary operations. Each layer of systems organized this manner looks like a “compiler” for the next layer.
We won’t dive further into the details of such an implementation. For an example, Conal Eliott’s “Pan” is an old image library that uses this approach to produce efficient image processing plugins for Photoshop.
Interlude: Generating specifications
The “layering” approach is about turning a function that directly computes something into a function that computes instructions to another system which can compute instances of such things. In the case of image processing, we’ll be turning images conceived as functions from coordinates to colour, to instructions to a GPU for processing images. Our domain model remains unaltered, while the implementation changes to improve efficiency.
Here are a few more examples of where you might’ve seen this pattern in action -
- DB interfacing functions that generate SQL
- JIT compilers generating instructions for CPUs from byte code
- “Display Postscript” in MacOSX (and NeXT) - instructions to draw on the screen, handled by the DPS driver.
- Apache Spark RDDs collect operations, optimize them all and perform them in parallel, adding failure tolerance (“resilience”) to the mix. The code to work with RDDs looks like functions that operate on arrays or lists to produce other lists/arrays.
Application: MapReduce
Many data analytics problems take the following form - you have a collection of some type of data and you want to compute a single value that summarizes some aspect of the collection. In our notation, we can express this computation as a function of the following type -
Coll X -> Y
where Coll X stands for a collection of values of type X. We’ll get into the
details of this collection later.
This formulation is too general and requires much expertise on the part of
someone setting up such a computation. To reduce the burden of having to answer
how exactly is a collection of Xs supposed to be turned into a single Y, we
split the problem into two sub-problems that are themselves a bit easier to
think about and tackle. First we turn Coll X into Coll Y and then we squash
Coll Y into a single value Y.
part1 :: Coll X -> Coll Y
part2 :: Coll Y -> Y
If we’re giving a mapping between X and Y the we can traverse the collection
of Xs and produce a new collection of Ys with one to one correspondence between
elements of both collections. So a generalization of part1 would be -
map :: (X -> Y) -> Coll X -> Coll Y
Similarly, if we know how to combine two Y values into a single Y value, we
can apply that repeatedly to parts of the collection, and therefore specialize
part2 to be -
reduce :: Y -> (Y -> Y -> Y) -> Coll Y -> Y
The first argument to reduce is a kind of “zero” value to produce when the collection we’re squashing is empty. Let’s work these out for a simple kind of collection - a tree.
type Coll x = Empty | Leaf x | Branch (Coll x) (Coll x)
What we’re saying here is that “a collection of xs is either empty or
has a leaf value or is a branch consisting of two such collections”. This
way, we capture the recursive structure of the tree directly using what are
called “sum types”. We’ve seen “product types” already - ex: (X,Y) which we
encountered when working with images.
Let’s try to specify map and reduce for such a collection.
map f coll = case coll of
Empty -> Empty
Leaf x -> Leaf (f x)
Branch left right -> Branch (map f left) (map f right)
reduce y0 f coll = case coll of
Empty -> y0
Leaf x -> f x y0
Branch left right -> reduce (reduce y0 f left) f right
While our map has an intrinsic parallel nature - with the left and right
parts independent of each other, it looks like reduce can only be done
sequentially. You might’ve noticed that we could’ve written reduce in the
Branch case as reduce (reduce y0 f right) f left and it would’ve still felt
correct. Sane invocations of reduce need reduction functions that produce the
same answer in both these cases. This is a large enough category that we can
formalize this split as a separate combination operation and rewrite reduce
accordingly -
combine :: Y -> Y -> Y
reduce y0 f coll = case coll of
Empty -> y0
Leaf x -> f x y0
Branch left right -> combine (reduce y0 f left) (reduce y0 f right)
Now, both map and reduce are individually parallelizable since parts of
the tree can be operated on independently. However, we’re still producing a
potentially large intermediate collection of Ys only to throw it away in the
reduce part of the computation. We can eliminate the intermediate structure by
combining both operations like so -
zero :: Y
mapreduce :: (X -> Y) -> (Y -> Y -> Y) -> Coll X -> Y
mapreduce f r coll = case coll of
Empty -> zero
Leaf x -> r (f x) zero
Branch left right -> combine (mapreduce f r left) (mapreduce f r right)
The above conception is a basis on which we can attempt to scale these kinds of computations based on user-supplied “mapper” and “reducer” functions. Now we turn to a more common kind of system and apply the same techniques to see what happens.
Application: Web sites
The structure of web services has evolved in sophistication quite rapidly over the past couple of decades. Our web services are still based closely on the original HTTP protocol. Nevertheless the architecture of clients and servers has changed structure over time. We’ll look at some of these changes and see if we can understand them from a system perspective using our new tools.
The Tim Berners-Lee edition
The original conception by Sir Tim Berners-Lee is a simple hypermedia architecture. A “browser” sends a request for a resource identified by a “URL” and the server returns a representation of that resource - usually HTML or an image. We may express this as -
app :: Request -> Html
where Input stands for a typical browser request. For the purpose of this system,
the app is entirely resident on the server side, with zero control over what the
browser does apart from whatever display control can be achieved via Html.
The AJAX edition
Over time, the cost of round trips were found to be bad user experience and we got AJAX. The basic conception of AJAX is that when a request is made for an “application” via a browser, the server returns a mixture of content and script code to run. The script code constitutes a part of the application that executes on the browser side and may make further requests for resources that may be HTML or Javascript of JSON or XML data. While user actions in the TBL edition always resulted in a round trip to the server, here user actions may be either locally completed or may entail a round trip, depending on the application’s need.
How do we model this?
I have no idea. You’re free to try though. I’d wager that people wanted something better because we lost the simplicity of the original web design and had nothing to replace it with.
The “ReactJS” edition
Reactive systems, ReactJS in particular, restored the simplicity of the TBL edition by providing an abstract sandbox within the browser. Within this sandbox, we can continue to pretend that we’re consuming input from the user and producing entire web pages in response. The library’s “virtual DOM” manages this cycle by efficiently matching updates to the browser’s DOM.
So we’re now free to model this the good old way -
app :: Input -> VirtualDOM
We can pretend the “virtual” DOM is real and think about our app as -
app :: Input -> Html
However, this is not strictly the system we’re modeling. While in the TBL edition clicks were the only form of interaction and each click was done on a URL. So this model was valid. Now though, inputs can be arbitrary clicks that don’t correspond to URLs, and can be key presses, touch interactions, and so on.
The system we’re looking to model therefore is a transformer that produces a
stream of Html from a stream of Input. Let’s call these “signals”. We can
express this idea as follows -
type Input = Click (Int,Int) | Key Int
app :: Signal Input -> Signal Html
In words, we’re now thinking of our app as a “signal processor” that transforms
a signal of input values (which change over time) into a signal of Html (which
changes over time in accordance). The user completes the loop by generating input
from what the browser presents based on the produced Html. We can capture that
pattern as a separate type constructor called SigProc, as follows -
type SigProc input output = Signal input -> Signal output
app :: SigProc Input Html
This buys us additional abstraction power as we’ve now moved away from the specific implementation of a “signal processor” as function that transforms one signal into another.
Factorization - the “Reactive” edition
If we permit an app to be conceived as just such a signal transformer, then we permit many concerns of representation between the input and the presentation to become mixed up over time. In reality, there is usually a smaller data structure that we care about preserving on behalf of the user - usually called a “model” - and the rest of the presentation system isn’t as essential as the model. It can be generated on demand given the model data. We can capture this factorization as follows -
app :: SigProc Input Html
model :: SigProc Input Model
view :: SigProc Model Html
app = model >>> view
where we use the >>> operator to compose two signal processors together to
make a composite signal processor.
As the sophistication of our UI increases, we usually find that what we’re
calling the “model” now begins to store transient state information that
pertains only to the presentation. For example, the state of a confirmation
dialog box, or the percentage progress of an operation. To capture this,
we can split the model into a pair - (Model, ViewState) - where what we’re
now calling Model is the thing the user really cares about and the ViewState
captures the rest of the transient stuff.
app :: SigProc Input Html
model :: SigProc Input (Model, ViewState)
view :: SigProc (Model, ViewState) Html
That doesn’t quite feel right. We want our model to deal only with
maintaining the Model object and to have nothing to do with the ViewState
ideally. This leaves us with -
model :: SigProc Input Model
view :: SigProc (Model, ViewState) Html
We now have a gap. We need something that now computes and maintains the
ViewState so that the view can consume it and produce the interface.
model :: SigProc Input Model
??? :: SigProc (Input, Model) ViewState
view :: SigProc (Model, ViewState) Html
Since this missing piece is mediating between the view and the model, we can
call it the controller.
controller :: SigProc (Input, Model) ViewState
We now have one kind of a “model-view-controller” factorization of our system. Note that this is very different from what is known as the “MVC pattern” which involves two-way interaction between the view and the model via the controller. What we have are processes that maintain a model, a view state and the output user interface.
All that is well. How do we see beyond the epiphany of the person who saw the MVC pattern while on the toilet seat? Surprise! We can continue this factorization further on our own!
Animations
If, for example, we want to have a model for UI featuring animations, we can draw on the convention of a “director-animator” division of labour in the animation industry to have a “director” process that at any given time tells us what the UI is expected to be doing, and an “animator” process that ensures that this expectation is smoothly met by moving components into their places over time.
app :: SigProc Input Html
model :: SigProc Input Model
director :: SigProc (Input,Model) Direction
animator :: SigProc (DT, Direction) ViewState
view :: SigProc (Model, ViewState) Html
.. where DT stands for “delta time” - a type denoting incremental time values
between consuecutive frame renders. We expect the Input to also capture this
information as time progresses. These “delta time” inputs come from the merged
stream of Input values and decide when the animator gets to update the state
of the widgets it is controlling. We’ll leave the function that composes these
four factors into the app as an exercise. One simplifying assumption can be
to keep Direction and ViewState to be the same type, with the input to the
animator consisting of an “intended value of ViewState” and its output being
the actual time-evolving value of ViewState.
PS: An implementation of this kind of factorization is demonstrated in the elm-anima library. The library implements retargetable and physics based animation facilities usable for browser-based interfaces.
For later
- Understanding control flow in various systems - covers blocking sequential flow, continuations, exceptions, server-side state using serialized continuations, delimited continuations, etc.
- A functional model for composing audio-visual productions.
- Notations
- Tala Keeper
- Demos
- Talks
GitHub · Twitter · Google+ · LinkedIn · RSS