I gave a talk at the “Mixed Nuts @ Pramati” meetup on 2019-08-24 10am-12pm on WebAssembly. This post contains notes from the talk - sort of almost-transcript.
Simul-posted at https://labs.imaginea.com/talk-the-nuts-and-bolts-of-webassembly/
The talk-n-workshop was setup to give the meetup attendees an idea of the current state of WebAssembly in relation to its evolution history and projected future.
Web presentation – PDF slides – PDF slides with builds – Powerpoint slides
History
WebAssembly as a performance accelerating technology that features in web browsers has a long history leading up to this moment that I find very interesting. The history covers both attempts at bringing high performance programmability to web browsers as well as the underlying technologies and their evolution that have contributed to it. I’m going to see if I can tell it like a story.
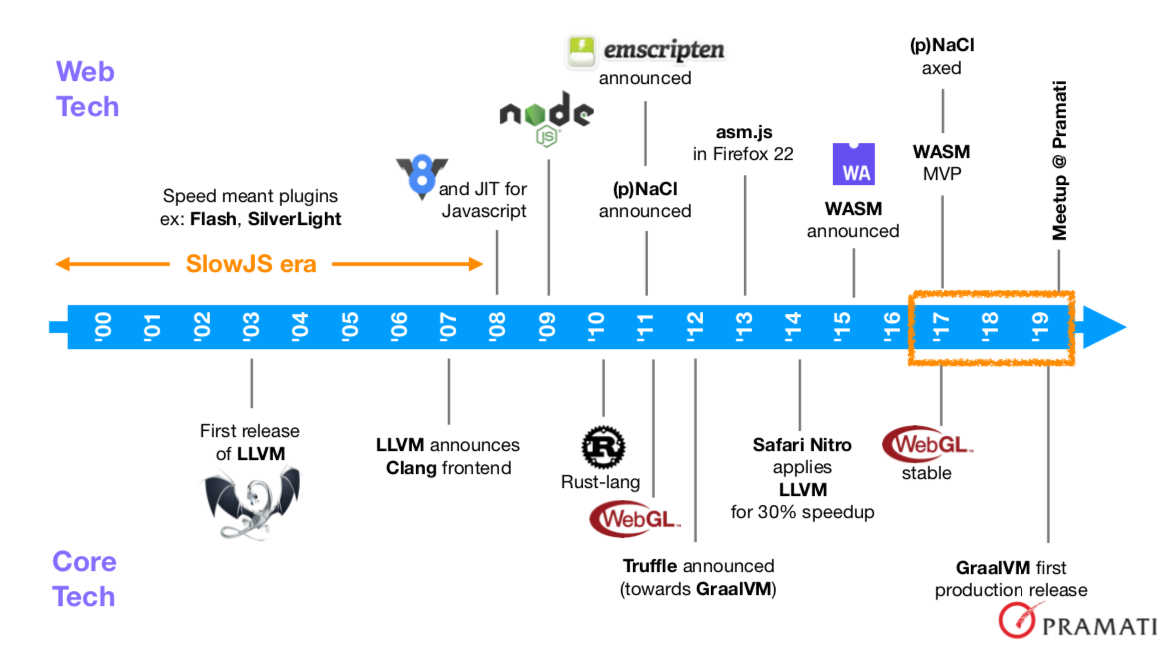
Before 2008, we had the “Slow Javascript era” which was pre-V8. JS’s role in a web browser was limited to doing simple actions/reactions. During this era, if you wanted some performant interactivity and computation within a browser, you had to use tech like Flash and Silverlight. They used browser plugin mechanisms to take ownership of a portion of the display area allocated to a web page and did whatever their programs told them to do within that portion.
During this period, in 2003, one significant project was launched that would have a huge impact in the evolution of in-browser high performance computing - LLVM. The “Low Level Virtual Machine” project is about building infrastructure components that can be reused within compilers for various programming languages - i.e. it was a “compiler infrastructure project”.
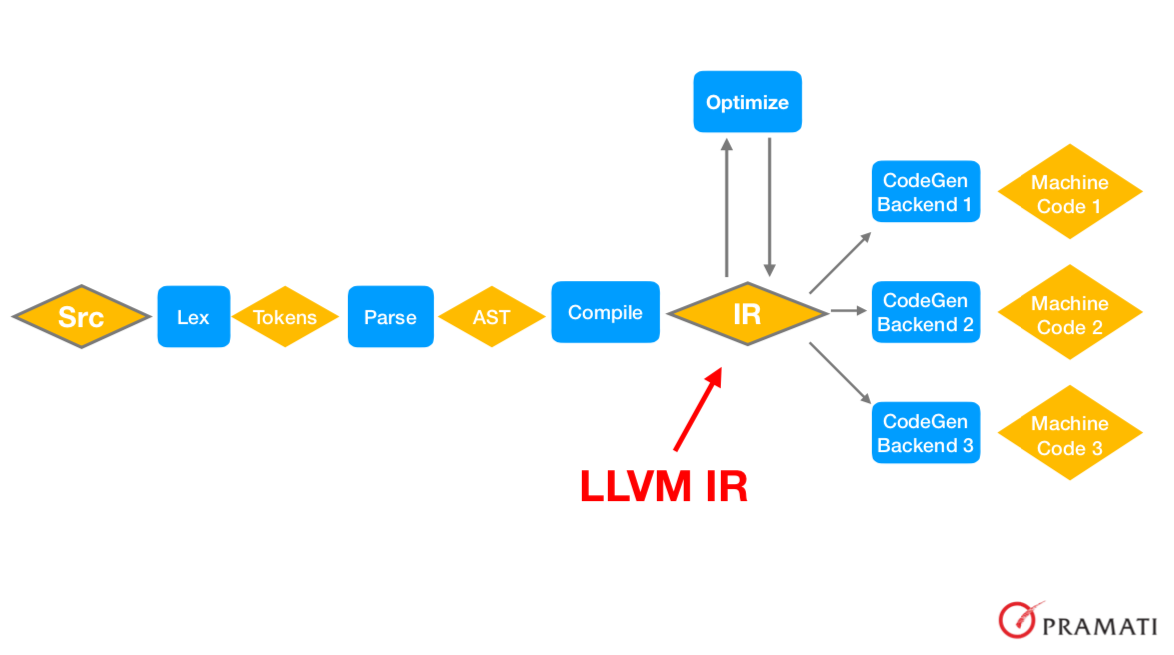
The process a piece of source code goes through before it becomes machine code is shown in the picture above. The source is parsed for tokens, the token stream is parsed into an “abstract syntax tree”, which is compiled into an “IR” or “intermediate representation” on which optimization algorithms are run like IR-to-IR transformations. The IR is then passed to whatever machine target backend is desired to finally get the machine code we want. What the LLVM project did is to specify a general enough IR that can be reused across multiple compilers. The IR therefore decouples compiler backend writers who need to know details about the machine and language designers who need to focus on the productivity, domain features and semantics of the language they’re designining. So language designers write compilers targeting the IR and backend writers produce IR-to-machine-code translators.
Around this time, Apple started sponsoring the LLVM project and adopted it as the basis for all of its platforms. Eventually, LLVM based tools took over the Apple developer ecosystem and today form the basis of Objective-C/C++ and Swift.
Trivia: Early on, LLVM was even present in the OpenGL drivers that shipped with MacOSX where it was used to translate/compile OpenGL shader language programs to run efficiently on the CPU when the available GPU didn’t support a feature.
So in 2008, V8 happens and JS gets a huge and ongoing performance boost from Google. Within a year, the potential for the Javascript+V8 combination for server-side programming is recognized and NodeJS is born. With that, event-driven IO gains huge visibility within the web application development community.
In 2010, Rust takes shape as a programming language targeting reliable systems programming. Under Mozilla’s wings, Rust is set to gain momentum and spread its influence into many areas as it evolves into an elegant language around the key feature of encoding object lifetimes within the type system, which powers Rust’s trademark “zero cost abstractions” design principle. Mozilla’s intent for Rust is initially for its multi-threaded Servo browser engine which it expects to give Firefox’s performance a boost.
Meanwhile, the availability of a high performance JIT compiled Javascript triggers ideas to treat JS as a compilation target. In 2011, the Emscripten project develops tooling that can translate LLVM bitcode (a binary form of the LLVM IR) into JS for running within browser contexts. The choice of LLVM IR here is interesting because it now becomes possible for any compiler that can generate LLVM IR to automatically target Javascript via Emscripten. It’s worth noting that the Rust compiler also targets the LLVM IR.
The “as close to native code performance as possible” movement gained another dimension in 2011 as Google announced the NaCl project - Native Client - and shipped it in Chrome. NaCl came with tooling and libraries that could take an Intel 32-bit compiled binary and run it safely within a browser context. The sandboxing technology behind NaCl ensured that the downloaded binary code can’t do wreak havoc on the user’s system and it also provided it with the necessary communication facilities into the browser environment via the “pepper” API. Soon, a portable version of NaCl called pNaCl was also released, which used LLVM bitcode instead of Intel machine code, and included a LLVM->Intel compiler to provide ahead-of-time compilation before running pNaCl code. Here again we see the crucial role played by the LLVM IR.
In 2013, Mozilla announced a specification for a high performance subset of Javascript they called “asm.js”, which was an offshoot of the work done on Emscripten. The specification permitted static determination of the types of Javascript variables and presented a programming model that permitted only functions that took numbers as arguments and produced numbers as results though the use of JS TypedArrays.
This constraint permitted asm.js programs to be AoT compiled into native code for high performance. While Mozilla built direct support for asm.js in Firefox, Chrome and Safari teams took the stance of continuing to optimize JS performance in general, with asm.js code benefiting without specific effort on their part. A particularly interesting moment came in 2014 with Safari’s Nitro engine improving JS performance by 30% using LLVM!
Let’s take a moment to appreciate what’s going on with Nitro. If you had native code that you compiled to asm.js using Emscripten via the LLVM IR, then shipped that code to a browser to execute, the browser translates the asm.js back into LLVM IR and compiles it into native code and runs it. Whoa! That is one small round trip calling for one big round of applause for the performance boost that LLVM enabled on the web.
The programming model of asm.js was very simple - the functions could only
read from and write to a fixed, pre-allocated block of UInt8Array memory.
They could additionally call Javascript functions, but only via an external
table that the environment is expected to provide. Given the simplicity of
this picture, here is really no need to tie it to Javascript and so we see
major companies - Google, Microsoft, Apple and Mozilla - coming together with
the WebAssembly specification in 2015. Around the time the WebAssembly MVP
was announced, which really launched WASM into the web world, all the vendors
were totally on board and Google axed the NaCl project in 2017 to put effort
into WASM. The WASM spec defined a stack based low level language to express
computations, a text format for human readability and an equivalent binary
format for compact transport.
Now let’s zoom into to the 2017-2019 period, as WASM really took off during this in a number of important directions.
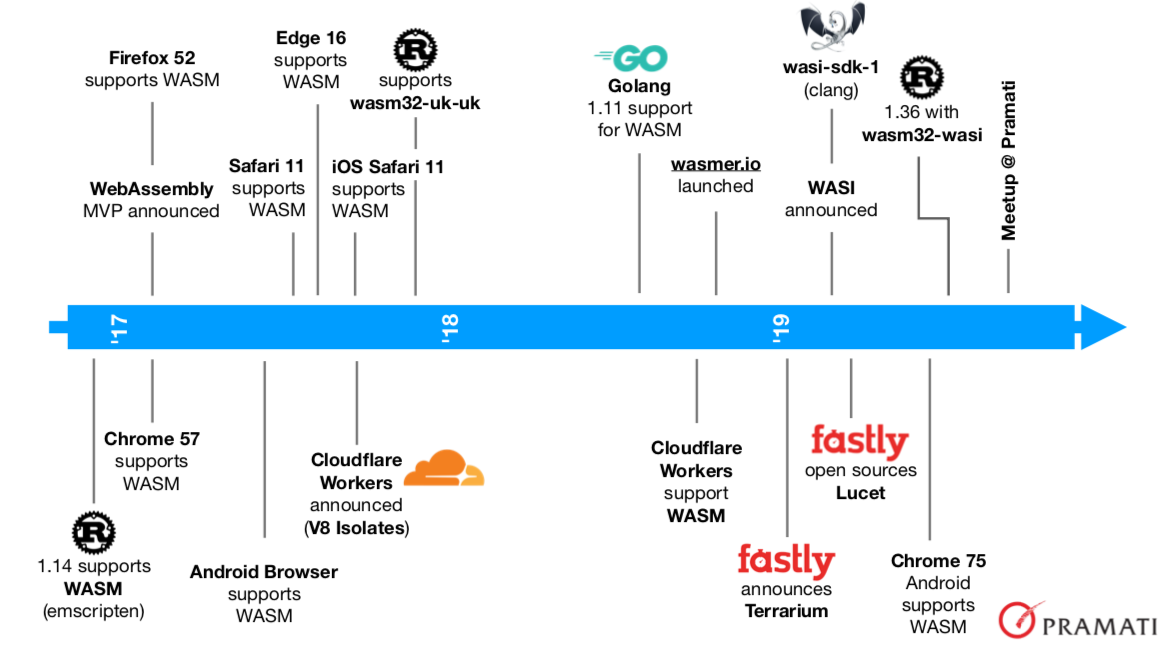
A little before the start of 2017, it becomes possible for Rust programs to
be compiled to WASM through the Emscripten toolkit. This made it possible to
use Rust for backend code, but also write some high performance in-browser
code in Rust as well. Then, with the announcement of the WebAssembly MVP, all
the browser vendors quickly roll out support for WASM in their browsers
within a year. Meanwhile, the Rust team plodded on and came out with support
for the wasm32-unknown-unknown target support towards the end of 2017. That
meant that the Rust compiler was no longer dependent on external tools to
compile down to WASM.
The last quarter of 2017 saw an interesting annoucement that we can say marked a milestone in the “serverless” paradigm of web application development - Cloudflare released Cloudflare Workers. Cloudflare is a CDN - a content delivery network - whose primary role until then was to push static content to geographically distributed “edge nodes” closest to the locations from where clients will need them. With Workers, Cloudflare gained the ability to serve these clients from the closest locations too, as developers could write small applications in Javascript to a specific Cloudflare published API and have the code be instantiated, run and shudown upon requests from clients. This is AWS Lambda-like functionality on steroids, from an infrastructure perspective. In about a year from the annoucement of Cloudflare Workers Javascript support, Cloudflare also announced support for running WebAssembly code alongside JS, bringing more power with tighter resource control into the product.
In 2018, the minimal specification of WASM triggered its experimental use
beyond web browsers, with Cloudflare marking a significant example. However,
the minimal spec also meant that it wasn’t possible to run WASM code on
servers without substantial wrapping code providing access to system
resources. The need for a standardized way to provide this functionality to
WASM code brought forth the WebAssembly System Interface or “WASI”
specification in the first quarter of 2019 by Mozilla. The announcement came
along with a first version of the SDK using which WASI-compatible WASM files
could be produced. The Rust team then rolled out support for wasm32-wasi
target for the Rust compiler, so you could build almost standalone binaries
that can run on any platform with a WASM-WASI supporting runtime. Wasmer,
a standalone WebAssembly runtime launched in the last quarter of 2018, added
compatibility for WASI and we could now run WASM binaries on multiple OS-Arch
combinations.
Early 2019 also saw the launch of another edge compute product from another CDN - Fastly - which launched Terrarium and the Lucet WASM runtime. The Lucet runtime can precompile a WASM module into native code that can be stored and transmitted, and Fastly open sourced the Lucet toolkit and runtime, adding to the rich set of tools that was cropping up in the WASM ecosystem.
That brings us to just about where we are now, at a the 7th Mixed Nuts @ Pramati meetup! I hope that bit of history was useful to see how WebAssembly came to be and the significant movers and shakers who made it happen. Next up, we’ll take a bit of a dive into WebAssembly, following which we’ll look at some trends to where we can see WebAssembly being applied in the near future.
A mini workshop on WebAssembly
In this mini workshop, we’re going to build a basic WebAssembly program, expose it to an embedding environment, write code to call functions in WASM and take a peek into the assembly format and stack-based evaluation model.
Setup
- Install the Emscripten SDK - https://emscripten.org/docs/getting_started/downloads.html
- Install the WASI SDK - https://github.com/CraneStation/wasi-sdk/releases (installs to /opt/wasi-sdk)
- Install webassembly npm module -
npm install webassembly - Install wabt - https://github.com/WebAssembly/wabt/releases
- Install wasmer -
curl https://get.wasmer.io -sSfL | sh
We’ll use the webassembly module to launch off, since it provides a more
minimalist environment for getting to know WebAssembly than other tools like
WASI and Emscripten.
pythagorus.c
Let’s say “hello math!” by writing an implementation of Pythagorus' theorem
as a function in WebAssembly and exporting it to an execution environment. Here is how you do that using the webassembly npm module.
#include <webassembly.h>
export double pythagorus(double x, double y) {
return sqrt(x * x + y * y);
}
Well, we didn’t write a WebAssembly program directly, but we wrote a normal C-language program to express the idea so that we can compile it down to WASM using the webassembly module as follows -
wa compile pythagorus.c -o pythagorus.wasm
You can then launch a nodejs shell and run the following program to load the generated WASM module and call our pythagorus(x,y) function as follows -
let WA = require('webassembly');
WA.load("pythagorus.wasm").then(module => {
console.log("pythagorus(3,4) =",
module.exports.pythagorus(3.0, 4.0));
});
The WA.load step combines two separate steps into one - a) the compilation
and linking of the WASM module and b) the instantiation of the module along
with the memory required to run it. It is worth pointing out these stages as
distinct because you can load a module once and instantiate many times
without incurring the compilation cost again. You do not have to load from
the WASM bytes every time. This separation is part of the WebAssembly
Javascript API spec which is supported in web browsers as well as in
NodeJS.
pythagorus.wasm
Now let’s look at the WASM file we produced via the disassembler that comes with the Emscripten SDK. Do wasm-dis pythagorus.wasm.
If you’re like me, you’re probably flabbergasted by all the stuff that you see there given that you wrote only 4 lines of code. Well, not all of that is strictly necessary, so we’ll strip away the scaffolding using the “-O” flag -
wa compile -O pythagorus.c -o pythagorus.wasm
wasm-dis pythagorus.wasm > pythagorus.wast
pythagorus.wast
The file we got from the disassembler should look like this (barring some pretty formatting differences) -
(module
(type $0 (func (param f64 f64) (result f64)))
(type $1 (func (param f64) (result f64)))
(import "env" "memory" (memory $0 1))
(data (i32.const 4) " \'")
(table $0 0 funcref)
(export "pythagorus" (func $0))
(func $0 (; 0 ;) (type $0) (param $0 f64) (param $1 f64) (result f64)
(f64.sqrt
(f64.add
(f64.mul
(local.get $0)
(local.get $0))
(f64.mul
(local.get $1)
(local.get $1))))))
The module is expressed as a single S-expression, which is a convenient representation of tree structures in textual form that is used by the Lisp family of languages.
The expression (type $0 (func (param f64 f64) (result f64))) declares the
type of our pythagorus function which is marked as exported by the
expression (export "pythagorus" (func $0)). The $0 is the internal
reference that is automatically assigned by the compiler for this function.
The definition of the function itself is the following expression -
(func $0 (; 0 ;) (type $0) (param $0 f64) (param $1 f64) (result f64)
(f64.sqrt
(f64.add
(f64.mul
(local.get $0)
(local.get $0))
(f64.mul
(local.get $1)
(local.get $1)))))
The first (param $0 f64) declares the first argument x and the (param $1 f64) declares the argument y, assigning them their internal and lexically
local references $0 and $1 respectively. The (type $0) sub-expression
also marks the type expression labeled with $0 as describing the type of
this function.
S-expressions
S-expressions take the form of parenthesized expressions as shown below, with the first term signifying the operator and the other terms giving the operands to which the operator is to be applied. The implication is that such an expression is then reduced to a value, which itself can be used as part of the argument list of another s-expression.
(op1 arg1 (op2 arg2 arg3))
-> calculate arg1
-> calculate arg2
-> calculate arg3
-> apply op2 on arg2 and arg3 to get result2
-> apply op1 on arg1 and result2 to get result3
We can see that the evaluation steps detail a post-order tree traversal of
the tree described by our s-expression. For our pythagorus function’s expression (the expression (f64.sqrt ...)), this would look like -
$0
local.get
$0
local.get
f64.mul
$1
local.get
$1
local.get
f64.mul
f64.add
f64.sqrt
If you do wasm2wat pythagorus.wasm, you pretty much see that above
post-order traversal. (The wasm2wat tool is part of the wabt toolkit you
installed during setup.) However, there is one small difference - the
local.get expects its argument to be specified after the operator in the
sequence. So the wat format isn’t strictly a post-order traversal.
(module
(type (;0;) (func (param f64 f64) (result f64)))
(type (;1;) (func (param f64) (result f64)))
(import "env" "memory" (memory (;0;) 1))
(func (;0;) (type 0) (param f64 f64) (result f64)
local.get 0 ;; <<-- SEE HERE
local.get 0
f64.mul
local.get 1
local.get 1
f64.mul
f64.add
f64.sqrt)
(table (;0;) 0 funcref)
(export "pythagorus" (func 0))
(data (;0;) (i32.const 4) " '"))
Apart from that one anomaly, it is easy to see how to read a WAST file and interpret the operations and perhaps even hand calculate functions if it comes down to it.
Something more useful?
While pythagorus.c was, hopefully, a useful illustration, here is something more useful - a small library to calculate euclidean distance between two “vectors” -
#include <webassembly.h>
export double *vec_alloc(int length) {
return malloc(sizeof(double) * length);
}
export void vec_free(double *vec) {
free(vec);
}
export double vec_distance(int length, double *x, double *y) {
double sum = 0.0;
int i = 0;
for (i = 0; i < length; ++i) {
double dx = x[i] - y[i];
sum += dx * dx;
}
return sqrt(sum);
}
The WASM file for this is bound to be bigger because we’re also introducing
local memory management through the use of malloc and free. The WASM file
will include implementations of malloc and free that will manage the flat
memory allocated to the module instance.
With some basic grasp of WASM, we move a bit further in and expand into a broader class of applications through WASI.
The WebAssembly machine model
I’ve mentioned the WASM model a couple of times before, but it is worth looking at it to see why such a minimal specification and execution model is valuable.
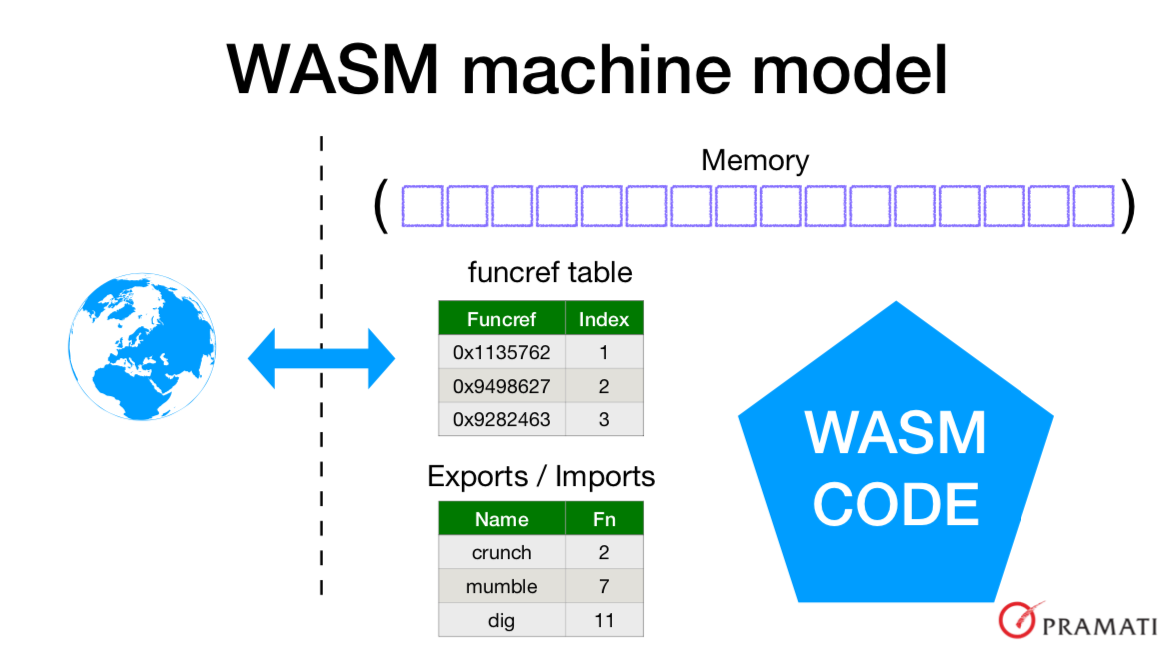
As illustrated, the WASM code can communicate with the outside world only through two things - a) the memory that’s been assigned for the code to work on, indexed starting from 0, and b) the “index” column of the “funcref table”. When a WASM module is linked, it can place references to its exported functions into the funcref table which the outside world will then be able to call. Likewise, the outside world can place function references into the table for the WASM code to call through the function’s index in the table. The WASM code does not have any reflection mechanism to examine or alter the contents of this table, which is what gives it its sandboxing properties.
The only other means is the memory region. So typically an environment seeking to use the WASM module will fill a portion of memory with input data, call some functions and read some other region of memory to get the output.
Given such a minimalist spec, and the fact that the WASM spec only indicates the following types - signed and unsigned 32-bit integers, and 32 and 64-bit floating point numbers - it is initially a bit difficult to see how this is general enough for the purposes that WASM is being claimed to be useful for.
The key is in the shape of the “funcref table”. For different purposes, we can come up with different specifications for what this table must contain and where, so that the environment knows how to use the WASM module and WASM module also has capabilities relevant to the environment that the code can call upon.
One such environment specification is WASI - the WebAssembly System Interface - which specifies bindings necessary for a WASM program to interact with POSIX-like environments.
WASI - the WebAssembly System Interface
The purpose of WASI is to permit normal unix-like programs that use file
system and network resources to be able to be run in environments such as
servers. That said, it does it in such a manner that the security properties
of WASM are not relinquished. While WASI is still under development, we do
have initial versions that we can use for basic programs. At the moment,
WASM/WASI doesn’t have support for some basic facilities taken for granted in
C/C++ programs such as exceptions and setjmp/longjmp which can be used to
express stack unwinding and continuations in addition to exceptions. Given
this, Rust’s approach to error handling without relying on exception
mechanisms and purely relying on function return values is a perfect match
for WASM, so I’d say Rust is currently the most suited language for WASM and
C/C++ will become more suitable as we go on and WASM gains some more common
features.
We’ll now go through a simple one to illustrate how WASM can be used to write
server-side tools in a safe manner. Below is standard C code for a program
that reads a text file whose name is given in argv[1], converts all lower
case characters (ascii only) to upper case and writes it out to an output
file whose name is given in argv[2]. This C program ucase.c will work with normal compilation and there is nothing WASM or WASI specific that we’re doing here.
#include <stdio.h>
int main(int argc, const char **argv) {
FILE *fin = fopen(argv[1], "rt");
if (!fin) { printf("Input denied!\n"); return -1; }
File *fout = fopen(argv[2], "wt");
if (!fout) { printf("Output denied!\n"); return -1; }
while (!feof(fin)) {
int ch = fgetc(fin);
if (ch >= 'a' && ch <= 'z') {
ch += 'A' - 'a'
}
fputc(fout, ch);
}
fclose(fout);
fclose(fin);
return 0;
}
As you see, the program is pretty straight forward. Now let’s compile it and
run it using WASM/WASI. To compile the program to be WASI compatible, you use
the clang version available with the wasi-sdk that you installed at setup
time. Pay attention to setting the sysroot correctly to point to the top
level folder from which clang can search for include headers and libraries.
If you installed the SDK at the default location (check for presence of
/opt/wasi-sdk) the you do not need to explicitly provide the sysroot.
SYSROOT=/home/srikumar/wasi-sdk-6.0/opt/wasi-sdk/share/wasi-sysroot/
clang -O3 --sysroot $SYSROOT ucase.c -o ucase.wasm
You should get a ucase.wasm file output in the current directory. Let’s try
to use this program to convert its own source code to upper case.
wasmer run ucase.wasm ucase.c /tmp/out.c
When you run that, you’ll see the message Input denied! being printed out
and the program will abort. We know that the file ucase.c is present in the
current directory, and yet fopen fails on that file. This is a first taste
of how capability based security is and will be implemented in WASI. You’ll
first need to tell wasmer to give permission to the ucase.wasm program to
access the current directory before it can read the ucase.c file.
wasmer run --dir=. ucase.wasm ucase.c /tmp/out.c
When you run that, you’ll now get Output denied!. Whoa! So we can’t even
write to /tmp/? Yes indeed. We need to grant it permissions to access
/tmp/ before it can create the output file.
wasmer run --dir=. --dir=/tmp ucase.wasm ucase.c /tmp/out.c
Play around with the file name now and see if you can get the program to output to the parent directory of the current directory by using
../out.cas the second argument. What do you get?
We can also do something more interesting. We can tell wasmer to pretend to
the ucase.wasm program that when it refers to /tmp/, it will really be
accessing an output directory in the current location instead.
mkdir -p output
wasmer run --dir=. --mapdir=/tmp:output ucase.wasm ucase.c /tmp/out.c
Now you’ll find the out.c file in ./output/out.c though the program
thinks that it is writing to /tmp. This is done by the --mapdir parameter
which specifies that the mapping.
This gives you a taste of how WASM programs, which looked very crippled when we considered its restricted machine model, can be used for real world applications. We’ll now probe the use cases further and see a number of use cases.
Where is all this headed?
Of course, WASM code must be runnable in web browser context or it won’t be meeting its original goal. I offer a shameless plug of a service I’ve been working on that relies on WASM to do complex audio signal processing in the browser - https://patantara.com - See example document Ganarajena Rakshitoham.
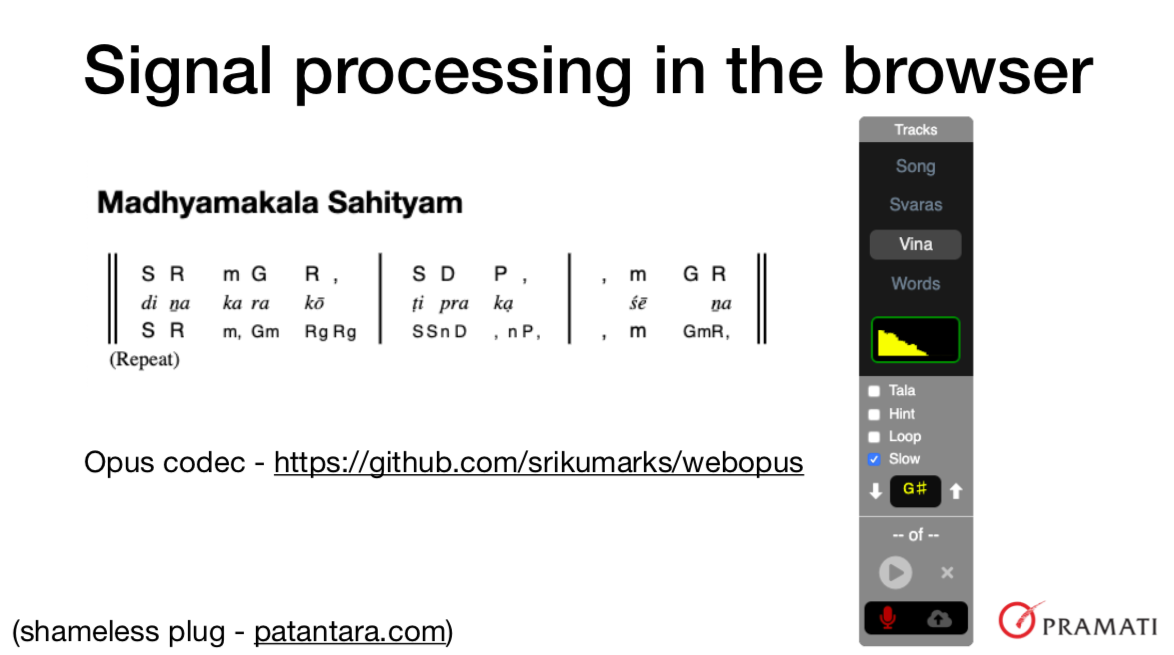
In patantara’s music player, you can change pitch without affecting tempo and also slow down the playback without affecting the pitch. The recording feature also uses a WASM packaged Opus audio codec to perform compression and decompression for more compact transmission to the backend. The wasm module is available at https://github.com/srikumarks/webopus .
With the obvious application out of the way, we’ll see how WASM can be used in cloud applications. But before we dive in there, it is helpful to recap some core cloud principles that are important today.
Core cloud principles
-
Fast deployment. The need to deploy code multiple times within a day requires that the deployment process - from build to ship - itself be fast.
-
Fast startup time. With the serverless paradigm gaining traction, programs are now being expected to launch when a request arrives, service the request and shutdown once they’re done. While AWS Lambda works around slow startup times by permitting keep-alive for a while in case another request comes in, that’s wasted resources for the cloud provider which translates into higher operational costs for the application. So we really want our programs to start fast - in less than a millisecond if possible - to make optimal use of resources.
-
Fast runtime. We want to be able to minimize cloud costs by being not needing to run high powered machines whereved possible. For this, we need our programs to run fast, and nothing runs faster than a program pre-compiled down to native code.
-
Low memory overhead. Machines with large RAM are also expensive in the cloud. So our programs need to use as little memory as possible. Runtimes which require a garbage collector are ill suited to meet this requirement as they may need 6x the RAM that a non-GC system for the same problem might require.
-
Secure execution. The most important of the list, a cloud provider would want to ensure that a customer’s application cannot compromise the security of the entire cloud platform and interfere with other customers' applications. For this reason, most cloud deployments use the strongest sandboxing tech available today - virtual machines. We’re relaxing a bit on that with the advent of namespaces and cgroups in Linux, which led to containerization, but still we can’t escape the fact that a security vulnerability in the container infrastructure may let an application escalate its privileges. For this reason, docker is not yet considered secure enough for some application environments that require stricter security properties such as in the financial industry.
Capability based security
Let’s discuss the security aspect first, since it is an extremely important aspect of cloud services. The notion of capability based security is gaining visibility recently and WASM/WASI fully supports the approach. We’ll see what it means shortly, but a quick one line description would be the following -
Capability based security: Your program can ONLY access the resources for which it has handles or can derive the handle from other handles.
We saw in the earlier case that our program could only open the ucase.c
file in the current directory once it was given a handle to the current
directory, which is what the --dir=. parameter did. That is an instance of
CBS in action.
Some other systems with CBS include Google’s upcoming Fuchsia operating system. The Cap’n Proto library created by the author of protocol buffers provides for CBS through transmittable object references. The https://sandstorm.io service is built using the CBS mechanisms provided by Cap’n Proto.

To give a quick flavour of how CBS works, consider three prople Anitha, Balu and Chandra. Anitha knows both Balu and Chandra - i.e. knows their phone numbers so she can call and talk to them. Balu wants to talk to Chandra, but does not have his number. The only way Balu can get Chandra’s number in this three person world is to as Anitha for it. If Anitha hands Chandra’s number to Balu, then he can call Chandra. However, she may refuse to do it for some reason too, in which case Balu is left without any means to contact Chandra.
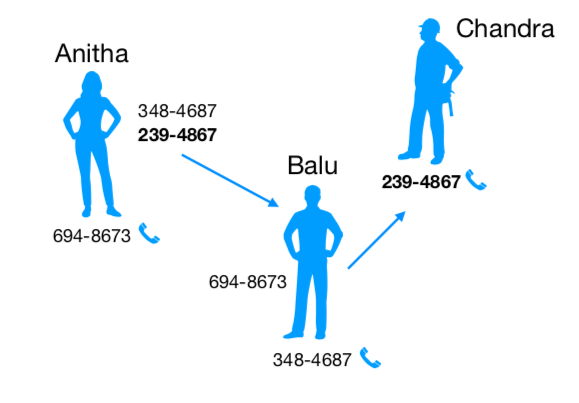
In this example, the phone number serves to identify a person as well as provides a means to contact that person and talk to him or her. So we say that the phone number provides a “capability”. This is similar to how pointers in object oriented systems both serve to identify an object as well provide permission to invoke the methods of the object. Another way Balu may try to contact Chandra is to try random phone numbers that are not his or Anitha’s until one hits the jackpot. This is how security breaches can happen and CBS systems avoid them by having capabilities be unguessable due to sheer size - like cryptographic hashes.
CloudABI
Now that we understand why for cloud providers it is important to be able to control the permissions that a program that runs on their infrastructure has to access system resources, we’re well placed to understand CloudABI, which is an API/ABI specification of only 49 functions through which programs can access storage and communication facilities in the environment. These functions are designed with CBS in mind so that the resource access can be controlled in a fine grained manner well beyond the user-based or role-based permission control systems more commonly found today. CloudABI programs cannot perform any operations that affect the global system and do not take the usual command-line arguments or environment variables.
Let’s look at a function to open a file as an example -
cloudabi_errno_t cloudabi_sys_file_open(
cloudabi_lookup_t dirfd, // Handle to directory containig the file.
const char *path, size_t path_len,
cloudabi_oflags_t oflags,
const cloudabi_fdstat_t *fds,
cloudabi_fd_t *fd
)
We see that without a handle to the directory that contains the file that we
wish to open, we cannot open the file. This is the mechanism behind --dir=.
in our earlier example. Let’s now see an example of network communication.
cloudabi_errno_t cloudabi_sys_sock_recv(
cloudabi_fd_t sock, // The socket to receive data from.
const cloudabi_recv_in_t *in,
cloudabi_recv_out_t *out
);
cloudabi_errno_t cloudabi_sys_sock_send(
cloudabi_fd_t sock, // The socket to send data to.
const cloudabi_send_in_t *in,
cloudabi_send_out_t *out
);
cloudabi_errno_t cloudabi_sys_sock_shutdown(
cloudabi_fd_t sock, // The socket to close.
cloudabi_sdflags_t how
);
These are the ONLY three functions available to work with network sockets in CloudABI. Notice that all three functions require that we provide a socket handle for the operation. This means that it is not possible for a CloudABI program to open a new socket connection to talk to a service and the environment must pre-open the socket and pass it the handle in order for it to do so. This gives the environment tremendous control over what the program can and cannot do in a fine grained manner.
We can now see the relation between the WASM machine model and its funcref table and the the CloudABI approach to CBS. For this reason, WASM and CloudABI are made for each other and we’ll hopefully see more widespread adoption of both of them in cloud services. The fact that the WASI interface spec is based on CloudABI says that WASM-WASI applications will find a natural home in CloudABI enabled services.
WASM in network edge servers
Content delivery networks (known as CDNs) place data centres at geographicaly distributed locations just before the last major distribution leg. They then copy over static content to multiple grographic locations and redirect client requests for these static resources - content - to the nearest servers to ensure speedy access to the resources.
Cloudflare and Fastly are such CDNs which have now added the ability to push services to these edge servers also, without the service developer having control over the machine .. even a virtual machine .. that is running the service.
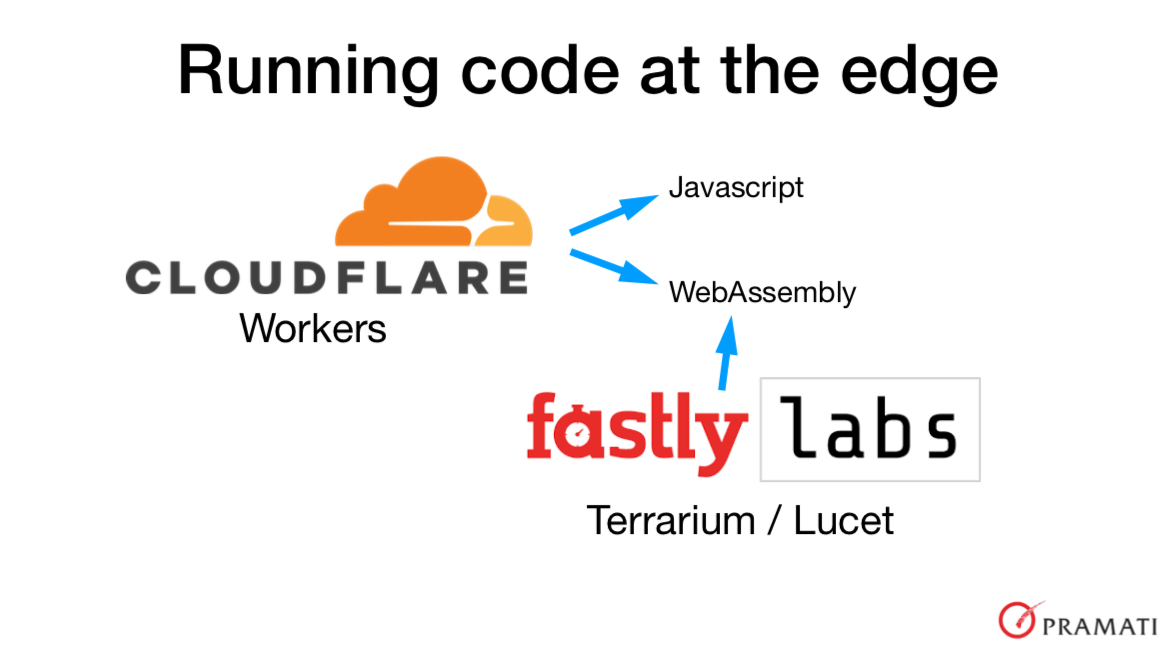
Cloudflare initially announced Cloudflare Workers with support to run custom Javascript code. The JS code is run within a V8 Isolate so that resource access to the code can be restricted to a specific API provided by Cloudflare and the JS code won’t be able to influence other workers'. This also permits the worker to startup very quickly compared to, say, docker containers. More recently, Cloudflare also added support to run WASM code within Workers.
Similarly Fastly Labs' Terrarium is also about running WASM code on edge nodes. It looks like Fastly is taking it further than Cloudflare Workers as they’ve built and open sourced their own WASM runtime called Lucet - a “sandboxing WebAssembly compiler”.
Thus we’re already seeing WASM spread its wings beyond the web browser home it was originally born in.
WASM in the kernel
The strong sandboxing properties of WASM also make it viable as a means to deliver secure code into operating system kernels. Wasmer is experimenting with kernel-wasm - a kernel module environment for executing WASM code within kernel space. For IO intensive applications such as reverse proxies, it may be beneficial from a performance perspective to run within the kernel in order to avoid kernel-space to user-space transits for data they shuttle.
eBPF - extensible Berkeley Packet Filters - is a linux kernel feature which already permits limited programmability using which application syscalls, for example, can be traced even in production. WASM may be able to play a similar role in the kernel.
Trusted computing
The linux kernel provides isolation between processes. However, the kernel itself has privileges to peek into the memory of and modify the activity of the processes that it governs. A typical security breach therefore is what is referred to as privilege escalation, where a process somehow gains the privileges of a kernel (I’m over simplifying it, but that will have to do) and is able to capture and leak secrets.

For certain classes of computations, such privileged access is not admissible and we’re also getting hardware support for enforcing such access control. Project Oak is an attempt to make a “trusted computing platform” by enabling the creation of environments calls “secure enclaves” into which even the kernel doesn’t have visibility and therefore cryptographic proofs of the activity of the process and the data it has can be produced can be created. These secure enclaves can communicate with each other through end-to-end encyrption. Project Oak uses WASM modules for the code that is permitted to run in the secure enclave, since it is possible to have control the activity of the code.
In the blockchain world, WASM for Ethereum is an initiative to derive a subset of WASM for implementing smart contracts. Towards this, eWASM works to reduce non-determinism and add facilities for metering code execution and contract functionality.
Other possibilities
We’ve seen a few areas markedly different from the original web browser environment which stand to benefit from WASM. Here are a few speculations about where else it can go -
WASM for deploying machine learning models?
Machine learning models are mostly organized as functions that predict some output from some given input, given a collection of model parameters trained from data. So they’re ideally suited for being packaged into WASM for deployment, since the code can be packaged along with the model data for repeatability, can run efficiently since it is AoT compiled and light weight to include only the code necessary to run the model.
Of course, very computationally intensive models such as the neural network based ones may require GPUs for maximal performance, which WASM doesn’t currently support. However, WebGL support is in the works and it is feasible to add another system interface to WASM to support GPU code execution, making it a viable option for deploying and scaling such models.
WASM for Kafka stream processing?
Kafka stream processors can currently be shipped as jar files that run alongside Kafka nodes to perform stream computations. WASM is another candidate which may have potentially far less overhead than Java for such stream processing applications. The memory overhead difference between WASM and Java for this task may be significant enough to increase throughput substantially, though that is only my speculation.
Similarly, distributed computing along the lines of Apache Spark also appears to be a great fit for WASM, as the code can be much simpler, easier to deploy and easier to scale.
WASM for database UDFs?
The strong sandboxing feature of WASM can be useful in writing fast analytics functions that run within database processes, for which we currently write UDFs in Java. The AoT compilation and predictable memory usage could be useful in such a high performance environment.
WASM for FPGA?
Well, this one’s taken - https://github.com/piranna/wasmachine - wasmachine
is “WASM for washing machines”.
WASM in network controllers?
Programmable network controllers - including switches and routers - are the key pieces enabling software defined networking. WASM may be suited for placement in these kinds of resource constrained and super low latency, high performance environments to gain bigger programmability and perhaps even place application level features such as key-value stores right at the networking hardware.
WASM on bare metal?
WASM is just code that can read from and write to memory. That makes it suitable as a packaging medium for code running on bare metail if hypervisors choose to directly support it with additions to provide access to key resources such as networking and storage.
Closing thoughts
We saw a bit of the history leading up to WASM and how the LLVM project contributed towards it through the LLVM-IR. It continues to aid WASM by enabling languages that compile down to the LLVM-IR to target WASM as a backend.
Though WASM originated in the context of providing high performance programmability for web browser based client side applications, it has applications well beyond browsers that we’re only beginning to see happen. WASM is a good choice for high performance code where the compute is more than any memory copy overhead for the data required for the compute … though that can also be designed around. In conjunction with WASI and the browser environment provided by Emscripten, it is also becoming the choice for porting legacy applications written in languages such as C/C++ to the browser environment. This includes audio/video signal processing, simulations, games and full fledged programming environments/IDEs. In this space, Rust is getting first class support for WASM due to its strong safety guarantees at the language level and minimal demands on the execution environment, and they may strengthen each other going forward. In the near future, we’ll see facilities such as threads, SIMD and WebGL added to WASM which should increase its power to the point where native code applications could start shipping as WASM for portability and availability without compromising performance.

- Notations
- Tala Keeper
- Demos
- Talks
GitHub · Twitter · Google+ · LinkedIn · RSS