(This post was originally posted on the Imaginea blog on 27 May 2016. That blog now no longer exists, so I’m reposting it here. I have The Internet Archive to thank for keeping a copy of the text and my colleague Srikant Patil for his help recovering the images originally presented in this post from an archive.)
In Fluid Concepts and Creative Analogies, Douglas Hofstadter gives centre stage to analogy making as a foundation for intelligence. Much of the book is occupied with an architecture for making analogies between letter patterns – i.e. a cognitive architecture for answering questions of the kind “if abb : bcc then eff : ?”. Hofstadter is brilliant at taking a basic question like how do we model human-like analogy-making computationally, and coming up with a small enough problem space that captures key problem features so we can actually have a go at it without being overwhelmed by the problem. I came across his book circa 2000 (probably 1998/9) and have been fascinated by both the problem and Hofstadter’s approach and thinking that went into it. The fact that his GEB:EGB had been an earlier favourite only added to the fascination.

In FCCA, Hofstadter talks about derivative projects – one of which (“Letter Spirit”) is about analogy making in the typography space : the question being “if : then : ?”. In a sentence, if I show the system a particular stylized presentation of the letters “abcd”, how do you get it to construct other letters such as “wxyz” in the same style. Once more, he displays the uncanny ability to construct a small enough space – “grid fonts” – in which he manages a few breakthroughs.
Fast forward to 2015, and we have a large number of teams exploring “deep learning” using deep convolutional networks for visual classification and object identification problems. The dominant complaint against neural networks has generally been that we know they work, but we do not have an understanding of how they work. The networks don’t “explain” their strategies in a way that we can grasp.
Google’s Deep Dreaming project is an interesting attempt at gaining visibility into the inner workings of a deep convolutional neural network trained on images. A Google engineer figured out a way to ask a neural network questions and get answers that we can understand … in the form of images. The neural network used in this case was trained to classify images from the ImageNet collection organized around the WordNet ontology.
The layers of a deep convolution neural network (DCNN) that are closer to the input tend to look at spatially local features and the layers deeper down tend to be concerned with higher level and even conceptual features. Taking off on this basic idea, we’ve recently had teams try their hand at the same content-style separation problem that Hofstadter tried to tackled nearly two decades ago. The neural-style github repo contains code that anyone can run and play with mixing two images by taking the “content” from one and the “style” from the other, with some beautiful and surprising results that would appear to put remake artists out of business.
Enter Fontli
At Imaginea, we run a social network for typoholics called Fontli as our designers have a passion for the field. Folks share typography that they catch in the wild or work that they’ve created themselves. Members ask others for font identification and tips, and tag what they’re able to identify themselves. They even police each other and prevent Fontli from turning into an instagram 🙂

Given that we’re into typography, we would love to have a system where we can take a picture of some type that we catch in the wild and apply it to text of our own choice! It is therefore only natural for us to ask how we can tackle the question that Hofstadter asked two decades ago, using DCNNs that are feasible today.
Not too fast though. What the neural-style project accomplishes is not exactly the problem that Hofstadter (and we) are interested in, but a related problem – given that you (the system) know how to classify a given massive object tagged collection of images, can you produce a rendering of an ad hoc presented object in the style of some provided visual artifact? So the question that we wish to ask is not exactly of the nature that the neural-style algorithm with the ImageNet based model can answer. It is closely related though.
That wouldn’t deter us from trying it anyway right? So we tried it with a bunch of images largely in three classes – type, patterns and semi-realistic pictures – with some surprisingly good and surprisingly crappy results. We wanted to try what “taking the style from an image” would do to a dead simple bland piece of text in black and white – the “content”, shown below.

Here is what we ended up with when we used the above image as “content” and a varied selection of “style” images. The images below were all rendered using the 19-layer network which is the default in the neural-style tool. The amount of content has been kept small in these images deliberately – the proportion varying between 5:1000 and 50:1000. Each image took about 10mins to generate on a g2.2xlarge instance on AWS.



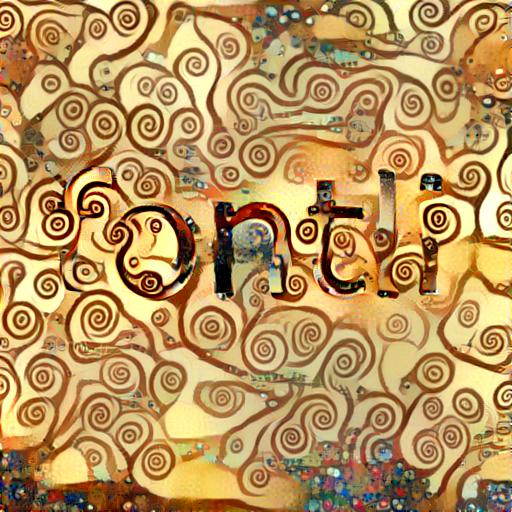
















What didn’t work
Realistic photographs did absolutely nothing. Also, since the ImageNet training set doesn’t attempt to teach typography to the neural net, we also didn’t have much success trying to use the letter styles from an image and apply it to new text. The results were mixed, with decent results some times, but head-scratchers at other times.
Paintings worked well ‘cos it appears to be easy for the neural net to “get” the content of a painting with the rest treated as noise … in our case the noise being the “style”.
Look on below.








To continue ..
What we’ve seen in this quick experiment is that the net trained on real world photos does not quite have the ability to read typography. This isn’t surprising since typography neither features strongly in the collection nor have such images been labelled well. That said, we can indeed make some very interesting images that present lettering and we hope to include this functionality in Fontli.
Holler in the comment section if you’d like to see this kind of word styling capability in Fontli!
.. and it looks like Hofstadter’s typography analogy dream is still a bit of a distance away. We would need to train a different network on manually labelled typographic works in order for the DCNN to show fluency in transferring styles from known art to other letters. The design of this training strategy for typography is itself going to be interesting and we’d like to step into a blue police box, jump to the future and check out the wonderful type that the trained DCNN will permit normal human beings to create!

(.. screwdriver warbling ..)
- Notations
- Tala Keeper
- Demos
- Talks
GitHub · Twitter · Google+ · LinkedIn · RSS